18 days ago, Duolingo released their newest language course: Yiddish. There has been an unsurprising amount of controversy around the course, which I will briefly explain, but there has also been a lot of confusion about the language itself, especially the relationship between spelling and pronunciation.
I wil l start with the caveat that while I am a trained linguist and I already spoke some Yiddish, I am an enthusiast and neither a native speaker nor a Yiddishist™️. That said, I am friends with people who are both, and I have been asking them my own questions, and keeping an eye on the questions (and conflicts!) that have filled my social media feeds in the last two weeks. This is not intended to be an academic work so much as a toolkit for people who are struggling. Note: I am going to be saying “Hasidic” and not “Hungarian/Poylishe/etc.” in the rest of this post, but I recognize that it’s a simplification and so should you. So let’s get down to tachles:
What kind of Yiddish are they teaching and why is there conflict?
Yiddish is complicated. Until very recently, it was incorrectly considered by many to be merely “bad German,” and it wasn’t until the 20th century that there was a concerted effort from a handful of linguists to study and describe Yiddish as its own language. Yiddish: A Linguistic Introduction by Jacobs has an excellent summary of the arguments that demonstrate conclusively that Yiddish is not merely a form of corrupted German, but is instead a fusion language descended in part from Middle High German, but also drawing on elements from Judeo-Romance languages, Hebrew, Aramaic, and Slavic elements. There are various other arguments about population movements and origins that are complicated, contentious, and not super relevant here.
Yiddish historically had dialects. Before the Holocaust, Yiddish was spoken across a large geographic area (Ashkenaz, or the heym). Historically, it could be divided into Western, Central, and Eastern, with further subdivisions: Northeastern, Central Eastern, South Eastern, and so on. These each had slightly different grammatical patterns, sometimes very different accents, and, of course, different words for the same thing. If you want to see maps of word and accent differences, @seydproject on Twitter are working hard on digitizing historical atlases of Yiddish.
Yiddish has new dialects too. Even before the holocaust, there was a push toward creating a standardized literary form of Yiddish. Its pronunciation was mostly Northeastern, but its grammar was drawn from other regional varieties and emerging norms in Yiddish literature. In many ways, what people refer to as YIVO Yiddish (for the YIVO Institute) is an imagined standard that wasn’t ever spoken natively by anyone, but that was a reasonable compromise for a cross-dialect, cross-regional “standard.” Separate from that, there are new dialects of Yiddish that are different from what people spoke 100 years ago, and that are spoken by millions of native speakers around the world — mostly in very “religious” communities (not that they’re actually more religious or more traditional than everyone, but they’re usually discussed in those terms). There was a melting pot of Yiddish in the Lower East Side roughly 100 years ago that may have been its own distinct thing, as well.
The new dialects have different grammar. Hasidic Yiddish in Brooklyn has a different grammar than YIVO standard Yiddish, than the dialects spoken in Europe a hundred years ago, and than the secular books people may be interested in reading in Yiddish. Case marking has all but disappeared in Hasidic Yiddish, so the definite articles der, di, dos are present in some formal publications, but in casual speech are almost always all de. This, in part, explains some of the pronunciations of di and der that slip in to Duolingo. Agreement on adjectives has likewise all but disappeared. In fact, case marking on pronouns even seems to be on its way out, with the dative fossilized in some forms, but accusative case encroaching on it.
The Duolingo team came to an ingenious compromise. The team was largely (all?) native speakers, but they wanted the course to potentially serve as a bridge between secular Yiddishists, who may be learning out of nostalgia or to read Sholem Aleykhem in the original, and Hasidim and other non-secular communities where Yiddish is the lived language of every day life. If you learn YIVO, you can’t speak to native speakers. If you learn Hasidishe Yiddish, you won’t grok the grammar in an Isaac Balshevis Singer novel. So what did they do? They chose to teach the spelling and grammar of YIVO standard Yiddish with the pronunciation of contemporary Hasidic Yiddish. This means if you want to speak with people, you’ll learn the vocabulary and pronunciation to be able to, and the grammatical changes you’d have to make are to have to do less conjugating and declining. If you want to read old books, or take a college class, you will know the academic grammar, and can figure out pronunciation from the standardized spelling. It’s literally a win-win. So of course everyone is mad about it.
Why is the spelling WEird?
There are two reasons the spelling doesn’t seem to line up with the pronunciation:
YIVO Yiddish has artificial mergers that contemporary native speakers keep distinct. It’s just like how New Yorkers keep the sounds in cot/caught or Don/dawn distinct but Californians cannot hear or reliably pronounce the difference. In this example, the Duo speakers are the New Yorkers.
Hasidic Yiddish has natural vowel shifts that led to mergers that YIVO Yiddish keeps distinct.
I will explain both in turn.
Orthographic ‘Mergers’
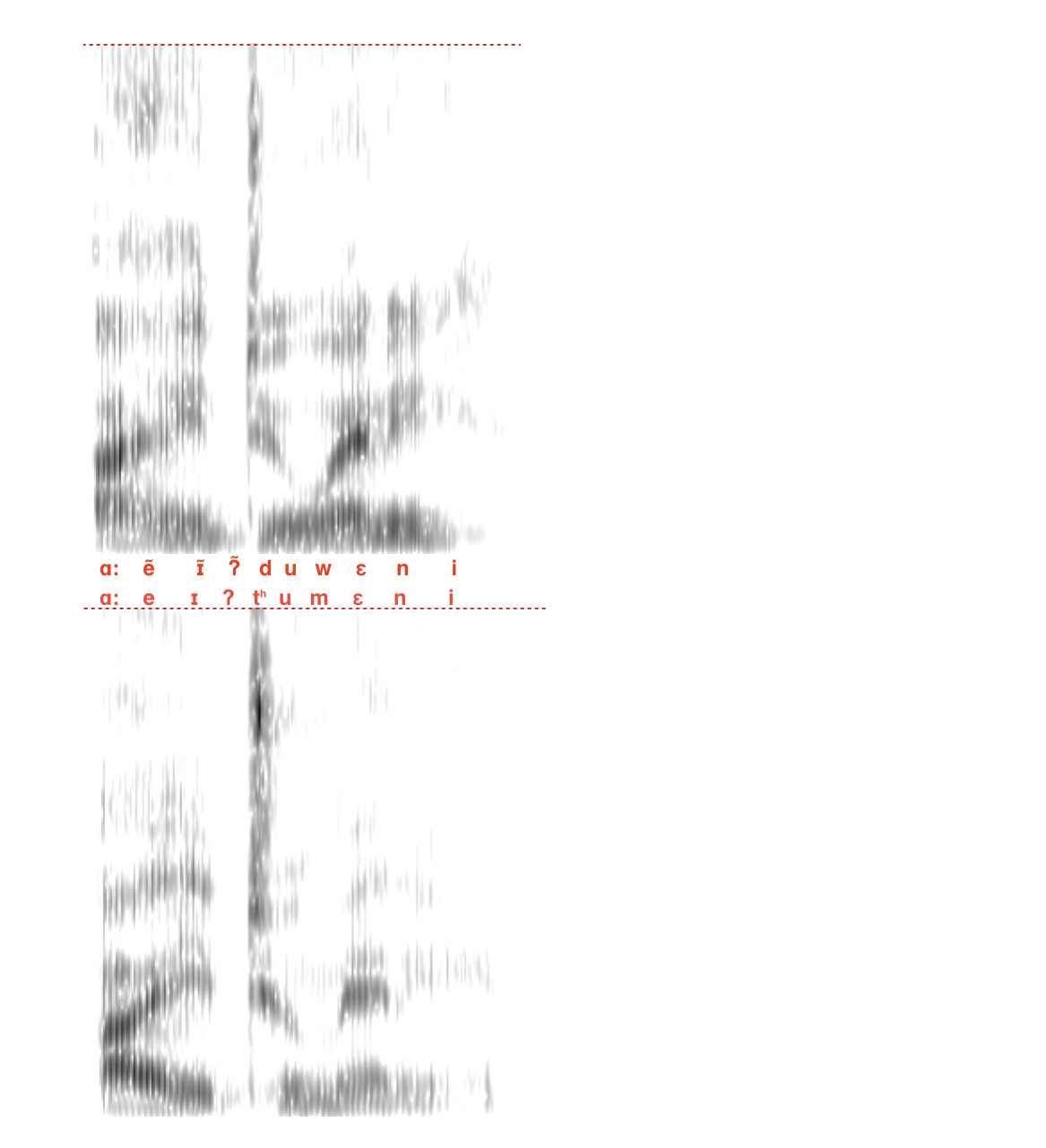
YIVO has collapsed two different historical vowel classes into “oy.” This is the main point of confusion from YIVO standardization: words like אזוי azoy ‘so’ and רויט royt ‘red’ are pronounced like they’re spelled, with an “oy” sound. [This is actually just a fact about written Yiddish, and not necessarily a decision made by YIVO, per se, as Isaac Bleaman helpfully pointed out]
But words like פרוי froy ‘woman’, הויז hoyz ‘house’, ברוין broyn '‘brown’ were not historically pronounced that way. They were historically, and are currently, pronounced like fro:, ho:z, and bro:n, where the colon indicates vowel length (if you listen closely, there’s what sounds like an off-glide as well). YIVO has — I cannot emphasize this enough — artificially collapsed two pronunciations that were historically distinct for many, many Yiddish speakers. So it’s not that the speakers on Duolingo are inconsistent in how they pronounce oy, rather they are very consistently pronouncing two different vowel classes differently.
Hasidic Vowel Shifts
There are certain patterns of change that languages follow so often that linguists are really not surprised by them. In fact, if you read Bill Labov’s magnum opus, Principles of Linguistic Change, there is an entire volume dedicated to predictable patterns of vowel change over time (with pages on pages discussing Yiddish vowel shifts!). This is not the place for it, but pretty much all of the vowels in English moved in what’s called the Great English Vowel Shift, and our spelling is weird because we have the old spelling with the new vowels. (Why is “Tim” not pronounced the same as “team” and “time” not “teamy”???). It has been helpful for me to think of the Hasidic pronunciations in Duolingo as what’s called a chain shift. That is, one vowel moves to a new place and another follows and takes its place.
If you are starting from YIVO Yiddish as an imaginary starting point, then here are all the changes you need to keep in mind to be able to navigate between YIVO and what you learn in Duolingo:
ey becomes ay. For most varieties of English, this means the vowel in English “say” is pronounced like “sigh”. You’ll see this in words like the ones for tea, one, egg, etc.
ay becomes long a. This is exactly the same as a Southern American accent pronunciation of words like “night” and “time”, and is what linguists call ay-monophthongization. So mayn ‘my’ becomes ma:n and man ‘man, husband’ stays man. “My husband” is two almost identical words but one is longer than the other: מײַן מאן ma:n man.
aw (as in coffee, hawk, caught) becomes o or u: That is, ָא is pronounced like it should be spelled with a vav. That’s how you go from YIVO vos iz dos to Hasidic vus iz dus.
YIVO ָא also represents more distinct sounds in Hasidic Yiddish (for instance, the oo of English “book”), so pay attention!
u becomes i. i stays i. This kind of merger happens all the time, and you should see the history of Greek if you think it’s bad in Yiddish. So YIVO vu ‘where’ and vi ‘how’ are both pronounced vi. Blumen ‘flowers’ (cognate with English “blooms”) becomes blimes. The word for “you” which is cognate with German du and English thou, becomes di. The word kumn ‘to come’ becomes kimn.
[Bonus: in some cases i becomes e in Hungarian/Hasidic sound shifts. Thanks to Isaac Bleaman for pointing this out]
This is not a historically accurate chain of events, but if you want to be able to navigate between, say, Duolingo and a college Yiddish course, here’s the pattern:
YIVO to Duo: ey > ay > aa and (some) a > u > i. You’ll have to just memorize oy for each word as they come.
Duo to YIVO: aa > ay > ey and (some) i > u > a. Spelling will tell you how it’s pronounced in YIVO if you just read a vav as u, a yud as i, and so on.
Vocabulary differences
Academic Yiddish has many of words that were simply made up by Uriel Weinreich when he wrote a dictionary of Yiddish. I love all of them (like der parol for '‘password’), even though some may never have been in widespread use. Many are borrowed from German or French.
Living Yiddish has many loanwords from the languages contemporary Yiddish speakers are in contact with. So YIVO fenster ‘window’ is more often than not now vinde. And the formal, academic geyn shpatzirn ‘going for a walk’ is vakn. Duo seems to be teaching the fun new stuff. If you want the old stuff, moving on to Weinreich’s College Yiddish after Duolingo would be a good next step [EDIT: an earlier version characterized the material in College Yiddish as “possibly made up” — The textbook is all legit, the dictionary may have some more fun neologisms. Thanks to Isaac Bleaman for pointing this out.]. If you really want to be good at Yiddish, congratulations, you’re learning two registers that way and you can vak with your friends but gey shaptzirn in formal writing.
[edit: there was a some discussion on Twitter of when to use vakn and when to use shpatzirn and it seems as though for some speakers who use both, vakn is goal oriented and shpatzirn is like a ‘stroll’.]
What’s the deal with R?
The variety of Yiddish spoken by the voice actors for Duolingo has what is called an “apical” r — meaning it’s tip of the tongue on the roof of the mouth, or as one person on Twitter put it, “Scottish R.” "YIVO Yiddish has a “uvular” r, pronounced at the back of the throat, which most people might know as the “French R.” The history of uvular r is a rabbit hole. Actually, just the study of r in general is a bewildering mess (trust me, I’m an expert), and which one a language uses has all sorts of downstream effects for coarticulation and language change over time. All a learner needs to know is that it’s Hasidishe = Scottish, YIVO = French. And the Hasidishe r is effectively the same sound that most Americans make when saying ts and ds in the middle of words, like ladder and latter. That’s why it sounds like the character’s name in Duolingo is “tseedl”.
More vocabulary differences
Yiddish English is not Yiddish. What this means is that words you may know in English, everything from schmuck to schvits to kvetch, may have a different meaning than you anticipated in Yiddish Yiddish. Babka, however, transcends language.
Good luck!
The above was definitely not an exhaustive, or even strictly correct description, but hopefully I showed enough of the correspondences that any of you out there learning Yiddish understand a little better how to navigate between YIVO and Duolingo pronunciations, and appreciate the compromise they made. I’m very happy with their course, even if they say ni and not nu, because it’s a fun, easy entree into spoken Yiddish, and I hope what I’ve written here helps others navigate the differences and get the most out of the course.
Here are some other resources:
For learning Standard Yiddish:
College Yiddish by Weinreich
Colloquial Yiddish by Kahn (there’s some fuzziness around “standard” pronunciation in this one)
Yiddish in 10 Lessons by Werdyger (also some fuzziness around “standard” pronunciation)
Basic Yiddish (grammar) by Margolies
For learning about Yiddish:
Some academics to follow:
I don’t know everyone working on Yiddish and I am bound to leave people out. People working today who have helped shape my (still rudimentary) understanding include Chaya Nove, Isaac Bleaman, Rachel Steindel Burdin, Zoë Belk, Lily Kahn, and others. There’s also the wonderfully named @jewyid on Twitter.
Good luck and happy learning!
-----
©Taylor Jones 2021
Have a question or comment? Share your thoughts below!