
I ran all Trump's tweets through a neural net to try and figure out the meaning of Covfefe. Here is what I learned.
Unless you've been living under a rock, by now you probably know that just after midnight two days ago, Donald Trump tweeted:
Despite the negative press covfefe
Twitter went wild, predictably. For two days now, there has been heated debate about (1) how to pronounce covfefe, and (2) what covfefe means. Yesterday, Trump's press secretary Sean Spicer declared that Trump meant to type covfefe, and that its meaning was known to Trump and a select few others.
In an attempt to get to the bottom of this mystery, I decided that semantic Word Embedding Models might be useful. I have written about such models elsewhere. The (extreme oversimplification) general gist is that if you treat some document or documents as a big bag of words, you can start to treat individual words as being related to one another by their position in a (high dimensional) space. Like words cluster together, dissimilar words are far apart in this vector space. The actual implementation is technically a "Feed forward neural net" that "fine tunes through back propagation," but this is all linear algebra and code and ignores the fun of it.
In order to try to get at the Mystery of Covfefe, I decided to train a word2vec (that is, word to vector) model in R, using Ben Schmidt's wonderful package in R. In order to do so, I first needed to gather all 30,999 Trump tweets (at the time I gathered them). I did so by cloning the Trump Twitter Data Archive (note: if you have a cool coding idea, chances are someone did most of the work already. I'm learning half of coding well and fast is just finding the appropriate already collected data, already written module/library, or already worked recipes).
Once I gathered all 30,999 Trump tweets, I needed to clean them. I did minimal cleaning on the data set, so I just made all words lowercase, eliminated punctuation, and eliminated common "stopwords" -- words like "and, are, in, at, be, there, no, such" etc. This has the effect of normalizing a bit, so sad and SAD! are treated as the same word. I have not yet gotten around to lemmatization: grouping words like ran, run, running all under "run", but I'm not sure to what extent that will really affect the output.
Having run the results through Word2Vec, I did some quick sanity checks by investigating which words are the closest to a handful of given words. Closest to could? would, honestly, and can. Closest to america? safe, again, outsider, make, lets. Closest to new? york, hampshire, albany, yorkers.
Clearly, it's working the way we would want it to, but are these really Trump's tweets? Closest to hillary? clinton, email, unfit, crooked, judgement, 33000, temperament. Closest to rosie? odonnell, theview, unprofessional, rude, bully. IT WORKS!
As I did before, I chose to visualize the word embedding space by using t-SNE (for t-distributed stochastic neighbor embedding). This does not preserve relationships exactly, but keeps near things near to one another and far things far. I present the full results for your enjoyment:
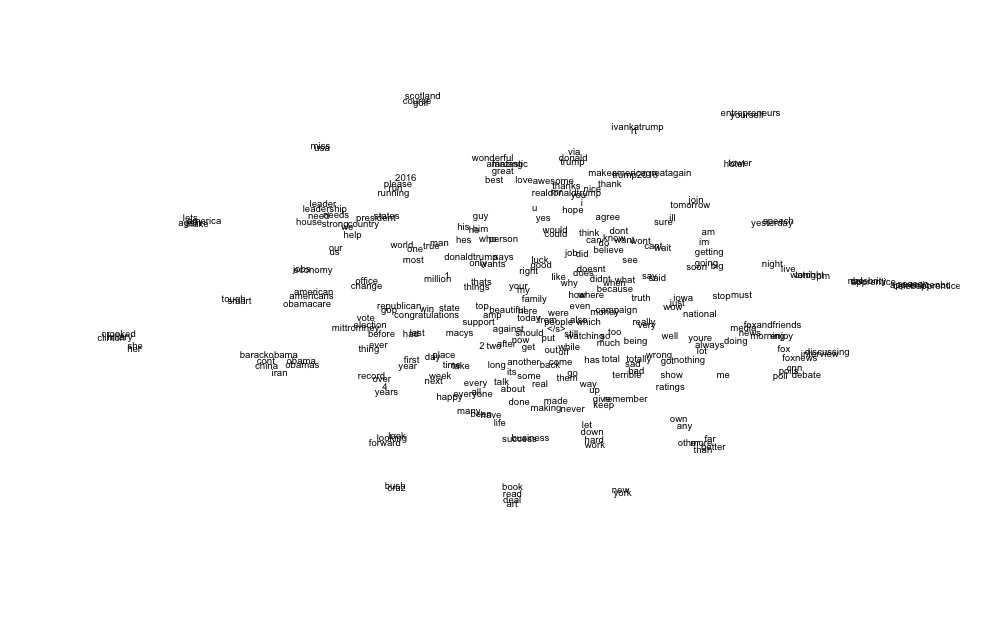
Tremendous. (Clicking "view image" should give a slightly bigger, clearer version)
Some really fun/interesting/hilarious clusters emerge. There's read book art deal. There's barackobama obama obamas china iran. There's my favorite: totally sad bad terrible wrong. There's the small cluster of bush cruz. There's scotland golf course.
What's missing? Covfefe.
So I decided to up the size of the model and include more words. Normally, you want 200-500 vectors in a model like this. I gave it 1000. The results are even better.

wonderful.
This model results in a cluster: realdonaldtrump mr awesome 2016. And, as a quality check, crooked is still right next to hillary.
But where's covfefe?
STILL not in the model. When I manually search for it, it shows up as excluded from these findings, and is returned next to realdonaldtrump, you, and i. Which is, frankly, perfect. Perhaps Covfefe is the word for all of us together with realdonaldtrump.
I know that's kind of a cop-out, but in the process, I learned a few other interesting things. In no particular order:
First, pick almost any word and the top 10-20 nearest words in either of the resulting vector spaces will include some negative sentiment. GOP? Establishment. Christian? Jailed. Beheading. Media? Fake. He's even hard on Russia in tweets: Russia? Traitor, laughs, taunting.
Second, closest to Ivanka? Daughter. For Barron, you have to wait till number 5 for "son" (most of the top 10 are family related words, or the names of family members).
Third, closest words to usa are miss, pageant, missuniverse, and perplexingly moscow. If you subtract pageant the closest word to usa is...balls. Checks out. Also, further down the list needs, trump, and businessman.
This brings me to one of my favorite findings. A classic example of word embeddings capturing something about semantics is that on other data sets these models have been trained on, you can add and subtract vectors meaningfully. So for instance,
paris - france + italy = rome
...which is intuitively correct. The classic example is:
king - man + woman = queen
Trump doesn't use the words man or woman all that much, actually, so in Trump's world:
king - man + woman = larry
I'm certain there are other relationships in the data that I've missed, but if there's anything that's clear from the above, it's that word embedding models really, really, really work (even if adding or subtracting "man" and "woman" are basically adding and subtracting zero, in Trump's tweets). I love the examples from cookbooks, historical newspapers, and RateMyProfessor reviews, but there's something really validating about these results, in part because Trump's speech (and twitter speech) is so colorful, and the above so clearly accurately captures it.
Finally, it looks like covfefe is off the charts, even for the surprisingly regular logic of Trump's twitter.
-----
©Taylor Jones 2017
Have a question or comment? Share your thoughts below!